SMP 架构多线程程序的一种性能衰退现象—False Sharing
很久没更新博客了,虽然说一直都在做事情也没虚度,但是内心多少还是有些愧疚的。忙碌好久了,这个周末写篇文章放松下。
言归正传,这次我们来聊一聊多核CPU运行多线程程序时,可能会产生的一种性能衰退现象——False Sharing. 貌似很高大上?No No No,我相信看完这篇文章之后你会完全理解False Sharing,并且能够在设计和编写多线程程序的时候意识到并完美解决这个问题。
OK,我们开始吧。
首先,False Sharing的产生需要几个特定条件:CPU具有多个核心,其上运行着的同一个程序的多个线程分别运行在不同的核心上,而且这些线程在修改同一个cache行的数据。说到这里你可能已经明白了,就是多核心修改同一cache行引起的。没错,因为现代CPU的每个核心都有自己的私有cache块,False Sharing产生的原因就是因为某个核心的线程修改了自己私有cache某行的数据,导致另一个核心的私有cache中映射到同样内存位置的cache行也被标记上脏位而被迫逐出,又一次从内存更新的缘故(保证cache一致性)。
如果两个核心运行的线程“此起彼伏”的修改邻近内存的数据,就会相互导致对方的私有cache中映射到该内存位置的cache行被频繁的更新。这样的话,cache的效果根本就没有体现出来。原理见下图:
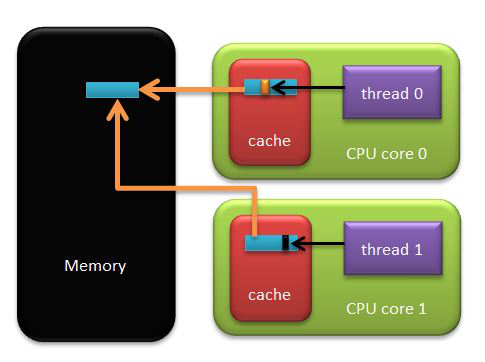
如果你对cache有疑问的话,可以看看我另一篇博文:《浅析x86架构中cache的组织结构》,为了便于描述,我也会把那篇文章的一些图片贴过来说明的。
接下来我们详细解释并且尝试用实验来证明这个现象。
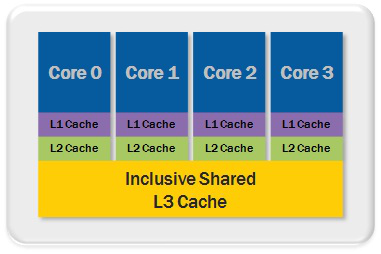
先贴一张CPU核心和cache的关系图(图片来自Intel Core系列处理器的白皮书):
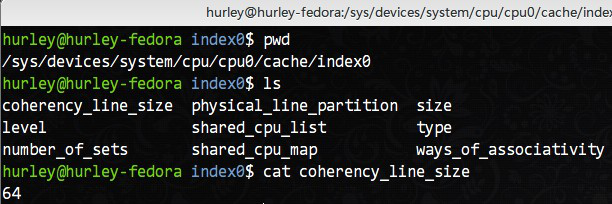
交代一下实验环境:Fedora 18 i686,内核3.11.10,CPU是Intel(R) Core(TM) i3-2310M CPU @ 2.10GHz. CPU L1d cache行的大小是64字节,如下图:
那么,触发False Sharing现象的条件已经很明确了。最简单的方法是创建两个线程,让它们同时去频繁的访问两个邻近的变量就可以了。那会不会正巧它们分布在不同的cache行呢?一般情况下代码只定义两个全局变量,因为编译器考虑到对齐放置,一般是会在一起的。 代码很简单:
1 |
|
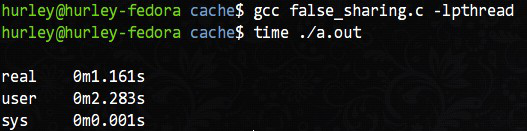
编译执行,用time命令计时,输出如下:
作为对比,两个线程并行执行改为轮流执行,代码如下修改:
1 | pthread_create(&thread[0], NULL, thread_0, NULL); |
同样的编译执行,结果如下:
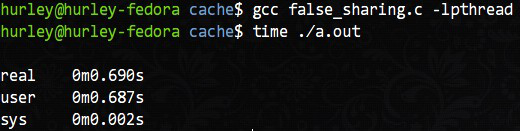
结果大跌眼镜吧,并行反而更慢了!False Sharing现象也许对小程序影响不大,但是对高性能服务器和并发度很大的程序来说需要倍加小心,没有锁也不见得没有性能陷阱。
解释清楚了,那怎么解决呢?其实很简单,用__declspec (align(n))指定内存对齐方式就好了,我这里的cache行是64字节,那就64字节对齐好了。变量定义代码修改如下:
1 | int num_0 __attribute__ ((aligned(64))); |
这样就可以要求编译器把这两个变量按照64字节对齐,就不会在同一个cache行了。然后把线程创建代码改回去,编译执行,结果如图:
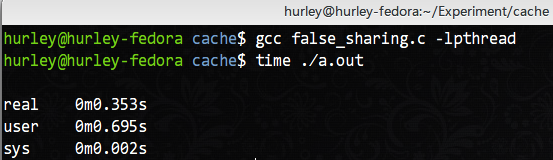
这才是并行的效率。
所以在设计多线程的程序时,当目标机器是SMP架构的时候,一定要留神这个问题。其实解决方法很好记,就是邻近的全局变量如果被多个线程频繁访问,一定要记得保持距离。

