cJSON 库源码分析
cJSON是一个超轻巧,携带方便,单文件,简单的可以作为ANSI-C标准的Json格式解析库。
那什么是Json格式?这里照搬度娘百科的说法:
Json(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于JavaScript(Standard ECMA-262 3rd Edition – December 1999)的一个子集。JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。这些特性使JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成。
更加详细的解释和示例请查看 http://www.json.org/ 主页。
其实简单说,Json就是一种信息交换格式,而cJSON其实就是对Json格式的字符串进行构建和解析的一个C语言函数库。
可以在这个地址下载到cJSON的源代码: http://sourceforge.net/projects/cjson/
__MACOSX目录是在Mac OSX系统下打包引入的临时目录,无视它。
简单的阅读下README文件,先学习cJSON库的使用方法。若是连库都还不会使用,分析源码就无从谈起了。通过简单的了解,我们得知cJSON库实际上只有cJSON.c和cJSON.h两个文件组成,绝对轻量级。
不过,代码风格貌似有点非主流,先用indent格式化一下代码吧。我个人喜欢K&R风格的代码,使用的indent命令行参数如下:
1 | indent -bad -bli 0 -ce -kr -nsob --space-after-if --space-after-while --space-after-for --use-tabs -i8 |
格式化之后,代码结构看起来清晰多了。
那么,从何处下手来分析呢?打开代码文件逐行阅读么?当然不是了,有main函数的程序大都是从main函数开始分析,那么没有main函数的纯函数库呢?那就自己写main函数呗。
cJSON作为Json格式的解析库,其主要功能无非就是构建和解析Json格式了,我们先写一个构建Json格式字符串的程序,尽可能的使其用到的类型多一点(事实上README文件里提供了不错的示例代码,我们直接借鉴一下吧)。代码如下:
1 |
|
编译运行后(编译时注意要链接数学库,参数行要加 -lm),运行结果如下:
1 | { |
打开cJSON.h这个头文件,我们可以看到每一个节点,实际上都是由cJSON这个结构体来描述的:
1 | typedef struct cJSON { |
结合这个结构体和上面相关API的调用,其实我们大概可以猜测出cJSON对于Json格式的描述和处理的方法了:
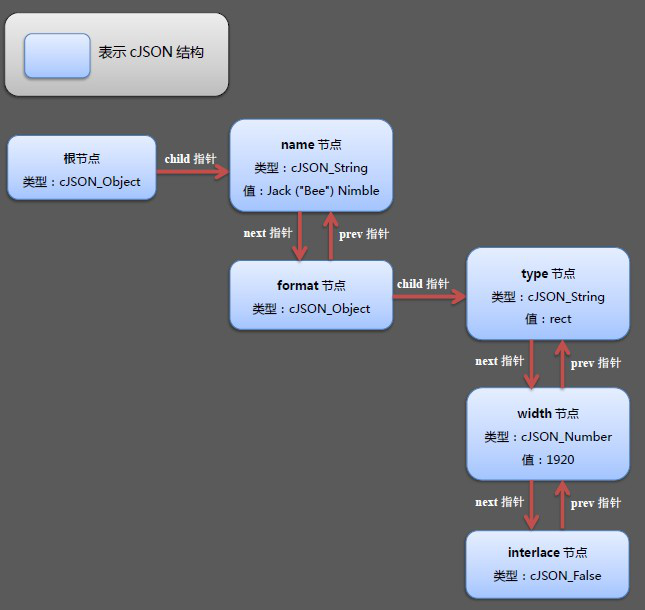
每一个cJSON结构都描述了一项”键-值”对的数据,其中next和prev指针显然是指向同级前后的cJSON结构,而child指针自然是指向孩子节点的cJSON结构。type类型显然是为了区分值的类型而设置的,在cJSON.h文件一开始就定义了这些类型的值:
1 | /* cJSON Types: */ |
很显然通过检测这里的type字段,就很容易知道该节点的类型以及其实际存储数据的字段了。其它的字段是什么意思呢?cJSON.h文件里的注释说的很明白了,valueint,valuedouble以及valuestring保存的是相应的值,string存放的是本字段的名字。
接下来分析程序的执行过程,编译参数加上-g,使用gdb调试程序,画出整个构造过程的函数调用图。具体的调试过程就不细说了,我捡一些关键点说说:
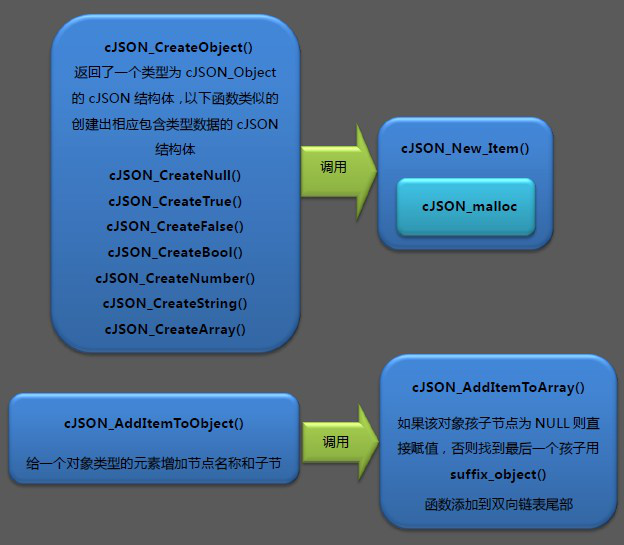
调试过程中,我们发现cJSON_AddStringToObject()等其实是宏定义,本质上调用的都是cJSON_AddItemToObject()函数,在cJSON.h文件中可以看到如下定义:
1 |
另外cJSON_CreateNull()等函数都是调用cJSON_New_Item()函数申请到初始化为0的空间构造相关的节点信息。构造过程中的函数调用图如下:
构造的Json字符串最终在内存中形成的结构如下图所示:
构造过程相对来说比较简单,数组类型这里没有涉及到,但是分析起来也很简单。
我们最后调用cJSON_Print()函数生成这个结构所对应的字符串。生成说起来容易,遍历起整个结构并进行字符串格式控制却比较繁琐。这里相关的代码还有递归清理这个内存结构的函数不再赘述,有兴趣的同学请自行研究。
构造的过程我们就说到这里,明天我们研究下解析的过程。
========
昨天简单的分析了一下cJSON对Json格式的构造过程,今天仔细读了读README文件,发现README其实说的已经很详细了。重复造轮子就重复造轮子吧,今天我们再一起分析解析的过程。
继续用之前构造的Json格式来进行解析,之前分析构造函数的时候,我们只是简单的分析了几个cJSON结构的构造过程,并没有涉及到各种类型的数组等构造。因为我觉得理解了一般的构造过程,更复杂的类型自己再简单看看源码,画画图就很容易理解。
学习一个事物一定要先抓住主线,先掌握一个事物最常用的那50%,其他的边边角角完全可以留给实践去零敲碎打(孟岩语)。
闲话打住,先上一段解析使用的代码:
1 |
|
程序运行输出:
1 | text: |
从这段代码中可以看到,解析过程就cJSON_Parse()一个接口,调用成功返回cJSON结构体的指针,错误返回NULL,此时调用cJSON_GetErrorPtr()可以得要错误原因的描述字符串。查看cJSON_GetErrorPtr()的源码可以得知,其实错误信息就保存在全局字符串指针ep里。关键就是对cJSON_Parse()过程的分析了,我们带参数-g重新编译代码并下断点开始调试跟踪。
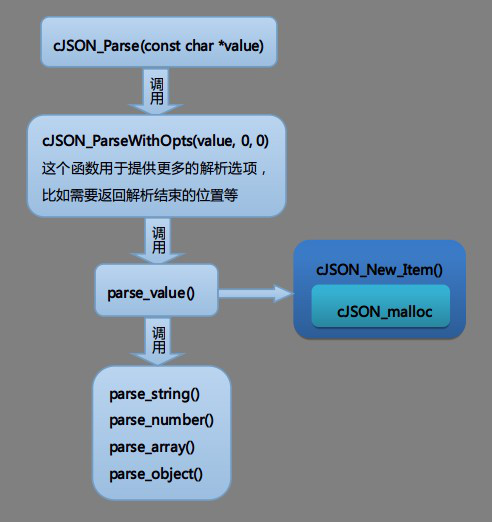
首先cJSON_Parse()调用cJSON_New_Item()申请一个新的cJSON节点,然后使用函数对输入字符串进行解析(中间使用了skip()函数来跳过空格和换行符等字符)。
parse_value()函数对输入字符串进行匹配和解析,检测输入数据的类型并调用parse_string()、parse_number()、parse_array()、parse_object()等函数进行解析,然后返回结束的位置。
函数调用的关系如下图:
这些函数之间相互调用,传递待解析的字符串直到结束或者遇见错误便返回,最后会构建出一个和之前结构一样的Json内存结构来,解析的过程就完成了。检索过程很简单cJSON_GetObjectItem()函数负责进行某个对象的自成员的名字比对和指针的返回。不过要注意这里采用了cJSON_strcasecmp()这个无视大小写的字符串比较函数,因为Json格式的键值对的名称不区分大小写。
这样cJSON库的整个构建和解析过程的主干内容就总结出来了,剩下的边边角角可以在这个主线分析结束之后再继续下去,比如Json格式化,解析出来的内存结构复制,从这个内存结构解析出字符串以及这个内存结构的递归删除等等留给大家自己进行吧。
P.S. cJSON_InitHooks()这个函数不过是cJSON允许用户使用其它的内存申请和释放函数罢了(默认是malloc和free),另外啰嗦一下,这个接口也可以用来检测内存泄露。只要实现malloc和free的包装函数,在其中统计和打印内存申请释放操作就可以了。

